
Photo by panumas nikhomkhai from Pexels
As part of our commitment to empowering performance marketers to Do More, With Less, Worry Free, the teams at TUNE are always searching for new ways to serve our customers. In this case, our Solutions Engineering team discovered a technology that simplifies how they deploy and support custom builds on our platform. As a result, they can now spend more time (and less money) working with more customers to build the solutions they need.
At TUNE, we pride ourselves on providing a flexible, comprehensive performance marketing platform that allows networks and advertisers to manage their digital marketing campaigns, publisher relationships, payouts, and more — straight out of the box, without having to write a single line of code. But sometimes, as with other fully managed SaaS systems, our customers require custom configurations, functionality, or integrations that can only be achieved by rolling up our sleeves and firing up the old code editor. Recently, we transitioned to a new technology that’s changing the way we build these solutions: serverless computing.
In this post, I’m going to walk through the issues we ran into with custom development, the steps we took to set up our serverless build process, and how this new methodology is solving the challenges of cost and scale.
Challenge: Keeping Up With Demand for Custom Solutions
When we first started the Solutions Engineering team at TUNE, we treated each custom customer build as a separate build. Most of these builds had a front-end component, which usually was deployed as a custom page on our platform, and a back-end component that consisted of a server, a database, and any other infrastructure required to keep the servers up-to-date and operational.
At first, this methodology worked for us. By having a small, lean team with a few complex custom builds, our method of provisioning and configuring a different server for each build worked for us. It allowed us to craft amazing experiences for our customers.
But as as the number of builds grew, we were starting to run into issues:
- Too many servers! As you can imagine, provisioning a minimum of two boxes per build led to us having too many servers. The sheer number of servers and all the pains that accompany them (such as security updates and backups) were costing us more time than we would like to admit.
- Keep those servers up. With each server being its own entity, we were responsible for making sure that each server was always up and operational.
- PHP ain’t for me. Most of our builds are spun from a base Docker PHP image. But as our team grew, we knew that forcing people to write their customer builds in PHP 5.0 when they were a Python wizard did not make any sense.
- This is getting expensive. With all our servers deployed on ec2/RDS, we were starting to see a significant monthly cost.
- Safety first. As these services handled sensitive customer data, we had to provide an authentication method for our public URLs to ensure the security of that data.
- Crons are tough. A lot of back-end services consisted of cron scripts, and we had no efficient way to manage these.
With these challenges surfacing, we knew we had to find a simpler, more cost effective way to provide back-end functionality to our customer builds. But after much debate and no clear front-runner for a solution, we were starting to run out of ideas. (In addition, with demand for new custom builds growing like crazy, time was definitely not on our side.)
Solution: Serverless Computing to the Rescue
If you have not heard of serverless computing, you may be wondering the same thing we were when we first heard about it. How can you execute code without a server? (Don’t worry; your fundamental understanding of programming is still correct, and no, we did not abuse the happy hour special before writing this.)
“Serverless” is a really confusing term for a new technology, because — let’s not be silly — there is definitely still a server executing code. So what exactly is serverless?
Serverless computing is a cloud-computing execution model in which the cloud provider acts as the server, dynamically managing the allocation of machine resources. – Wikipedia
Serverless cloud solutions allow you to build and run applications and services without thinking about the hassles associated with servers. Essentially, serverless computing allows you to do what you do best: write code.
The Serverless Setup Process
To show you the gist of how serverless technology works, I’ll walk through the steps we used to set up this functionality.
Note: There are many cloud providers with serverless functionality. In this example, we use AWS Lambda.
-
- First, create a new Lambda function and select “Blueprints.” Then, type “http” in the keyword field, and select either the Python or Node microservice-http-endpoint. (Blueprints are precrafted code blocks meant to make development faster. How awesome is that?) Once you have made a selection, click “Configure.”
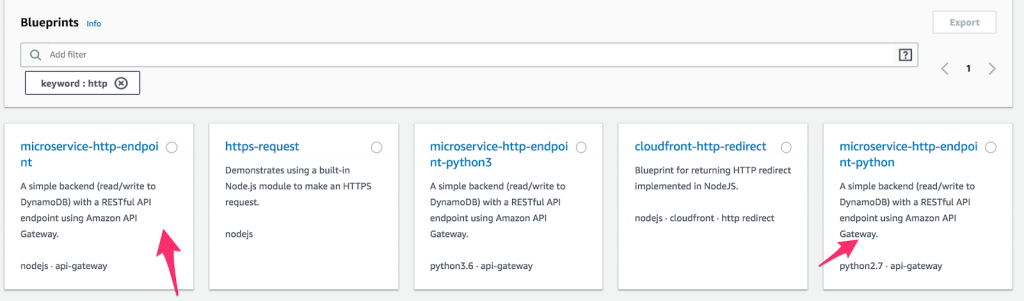
How to configure a function on AWS Lambda.
- Add a function name and role. Then select an API Gateway trigger with the security option “Open with API Key.” This API gateway will provide a public URL that will trigger your Lambda function. Adding the API key provides an authentication method, which is highly recommended.
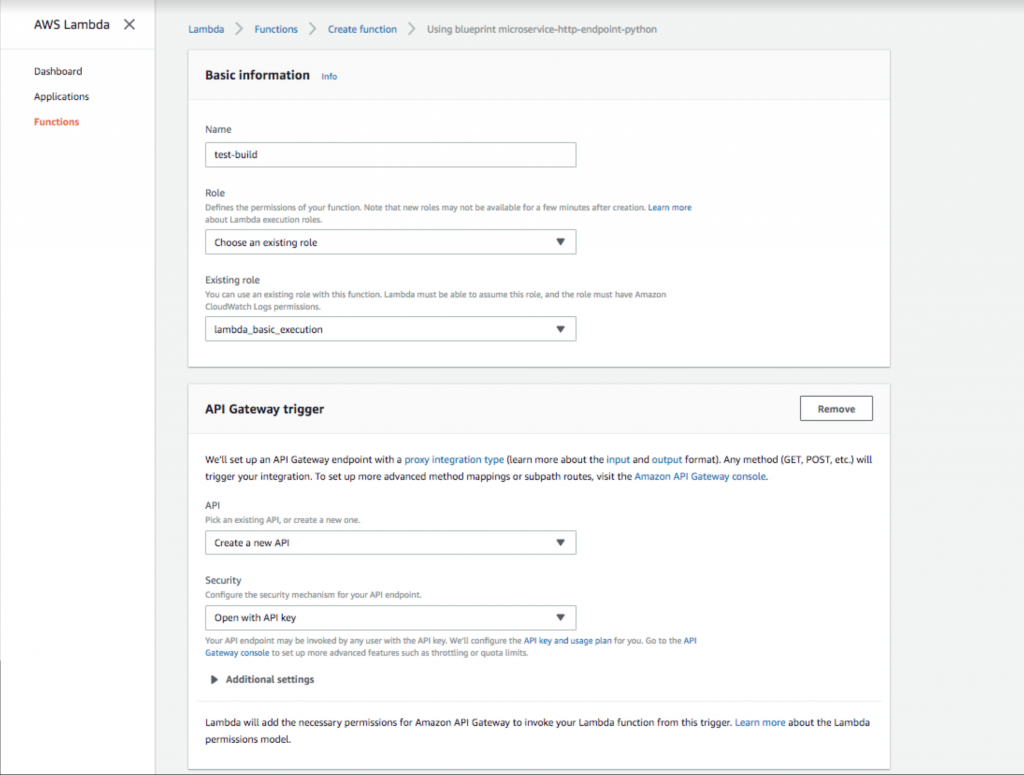
Setting up an open API gateway key in AWS Lambda.
- Once you create the function, you can now make configurations to your code. As you can see, the blueprint has already given you a cool entry point hook that allows you to interact with a Dynamo table (if you are looking to add a database). Whatever is under the lambda_handler will be executed when the public URL is loaded. Since we are also adding a database, let’s go to Dynamo and create one.
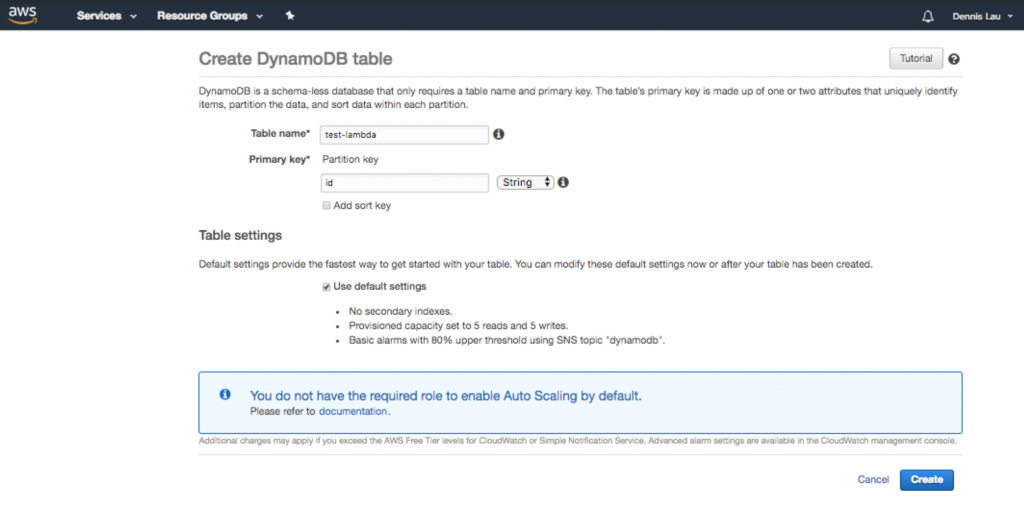
Creating a Dynamo database table in AWS Lambda.
- Once the Dynamo table is created, let’s make a call to this Lambda function from a public URL. Go back to your function and click the “API Gateway” icon at the top. You should see that the endpoint and API key have already been created for you.
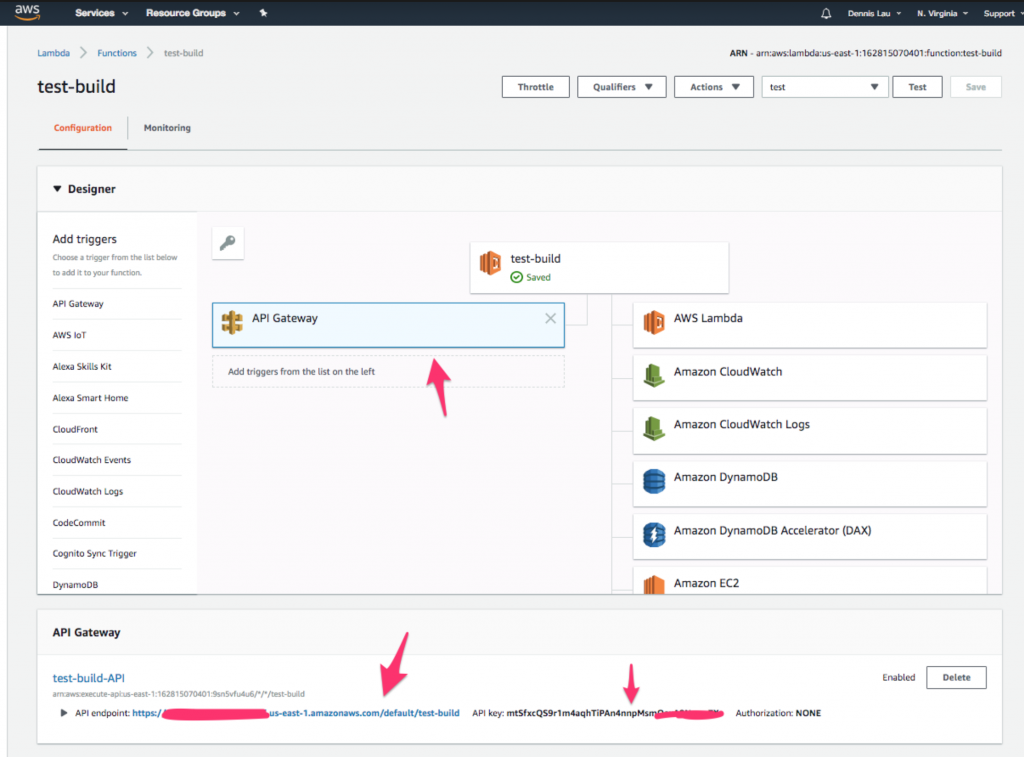
Where to find the API Gateway icon in AWS Lambda functions.
- Now open up the terminal and add the API key under the “x-api-key” header, then add the table name you created under the TableName query string parameter.

Enter your key and database name in the terminal to finish.
- First, create a new Lambda function and select “Blueprints.” Then, type “http” in the keyword field, and select either the Python or Node microservice-http-endpoint. (Blueprints are precrafted code blocks meant to make development faster. How awesome is that?) Once you have made a selection, click “Configure.”
That’s it! You now have a working, secure back end connected to a database. All it took was five easy steps.
How Serverless Computing Addressed Our Challenges
Now that we have shown you how to set up serverless builds, let’s take a look and see how this cloud-based model fares against our checklist of issues.
- Too many servers! Serverless … meaning no more servers, right?
- Keep those servers up. Since serverless computing is managed by the cloud provider, you get the benefit of having these providers (along with their battle-hardened, proven methods) to monitor your servers. For those of you who want to play Sherlock Holmes, you can also see all the server logs output by your function on Cloudwatch.
- PHP ain’t for me. Serverless models allow you to write in C#, Python, NodeJS, Go, and even Java.
- This is getting expensive. With serverless solutions, costs are metered based on the execution time (per 100 milliseconds) and amount of data transferred. Unlike paying per month, which includes time your servers stand idle, you are only paying for what you use. With costs as low as $0.000000208 per 100ms of execution, serverless computing could save you a significant chunk of cash.
- Safety first. Is serverless safe? With a built-in API key authentication system, you bet it is.
- Crons are tough. With a cron management system natively built on Cloudwatch, just set a time window and forget about it. Cloudwatch handles all logging and execution.
Final Thoughts
For the Solutions Engineering team here at TUNE, moving to serverless computing has been a game changer. Its ease of use, cost savings, and agile-friendly features have changed the way we handle all new customer builds. Serverless cloud-based solutions are set to change the world of server-side computing. I don’t know about you, but one thing is for sure: the TUNE Solutions Engineering team is ready.
To learn more about the TUNE platform and the custom development services we provide, visit our Professional Services page.
Author
Becky is the Senior Content Marketing Manager at TUNE. Before TUNE, she handled content strategy and marketing communications at several tech startups in the Bay Area. Becky received her bachelor's degree in English from Wake Forest University. After a decade in San Francisco and Seattle, she has returned home to Charleston, SC, where you can find her strolling through Hampton Park with her pup and enjoying the simple things in life.

